OpenAI is a research company that works on artificial intelligence (AI) with the stated goal of bringing it safely to humanity at large. This group works in many areas of AI like machine learning, deep learning, and robotics.
They are famous for the release of ChatGPT, which prompted the current explosion in direct-to-consumer generative AI.
Table of contents
GPT Models
Artificial intelligence (AI) continues to transform different industries, with notable advances in language models like OpenAI’s Generative Pre-trained Transformers (GPT).
The history of OpenAI’s language models, particularly the GPT series, is a fascinating story of technological progress. From its earliest incarnations to the most recent, GPT-4.1, each iteration has moved generative AI forward.
GPT-1
The adventure began in 2018 when OpenAI unveiled the first Generative Pre-trained Transformer (GPT) model. GPT-1 was a breakthrough in natural language processing (NLP), using 117 million factors to create human-like writing depending on context.
It represented an advancement in machine learning by revealing the possibilities of pre-trained transformers. As a model, it is an improved version of the original Transformer design that focuses solely on the decoder. That emphasis enables GPT to excel in text production because it is trained to anticipate the next word in a sequence based on the previous ones. To do this, it makes use patterns it analyzed from a massive body of online text.
GPT models, starting with GPT-1, are trained in two main steps: pre-training and fine-tuning.
First, in pre-training, the model learns from a massive amount of text, mostly from the internet. It discovers patterns in language, grammar, context, and style. By the end of this step, the model can generate text and handle basic language tasks.
Second, in fine-tuning, the model is trained further on a smaller, more focused set of data, often with human feedback. This makes it better at specific tasks, like summarization, translation, or following detailed instructions.
GPT-1 was the first model to use this two-step process. It showed that pre-training on large amounts of text, followed by fine-tuning, could create a model that understands and generates human language well. This approach became the foundation for all later GPT models.
GPT-2
Released in 2019, GPT-2 builds on the foundation created by GPT-1, increasing the model to 1.5 billion parameters. This significant increase in scale allowed GPT-2 to create more coherent and contextually relevant text, giving it a more potent tool for a wide range of NLP applications. The GPT revolution had begun.
The initial model, GPT-1, contained 117 million parameters, making it a revolutionary model for its time. However, GPT-2 has 1.5 billion parameters, much exceeding GPT-1’s learning capabilities. GPT-2’s design, with its expanded amount of parameters, contains more layers, and larger layers enabling it to process data more precisely.
GPT-2 was also trained on a far larger dataset. We have said that GPT-1 was trained on an abundance of data acquired from webpages and books. GPT-2 was not only trained with more data, but the data was also more carefully selected. The goal was to provide more varied and nuanced instances of language use.
Finally, while both models were trained using unsupervised learning approaches (learning from patterns present in large amounts of data), GPT-2’s training was optimized to handle its bigger scale. This required adopting more advanced strategies to efficiently train such a big model without sacrificing learning quality.
GPT-2 employed gradient checkpointing, mixed precision training, dynamic batch scaling, and a variety of other approaches. This was done to guarantee that not only the final model but also the training method are optimized.
GPT-2 offered improved text production thanks to its greater model size, resulting in more accurate and diversified output. It is still in use in data science today because of its small size (relative to later models) and versatility, capable of handling a range of simple applications, including summarization, translation, and question answering.
GPT-3
Released in June 2020, GPT-3 was a huge step forward, with 175 billion parameters. This tremendous rise in model size fundamentally changed natural language processing and creation. OpenAI made an even greater jump than when it upgraded from GPT-1 to GPT-2, with the latter being more than 10x times larger than its predecessor. In comparison to GPT-3’s 175 billion parameters, GPT-2’s 1.5 billion parameters look very modest.
That large increase in parameters enables GPT-3 to get a far better comprehension of language and context. GPT-3 was also trained on an even bigger corpus of text data than GPT-2. As a result, it integrates more diverse sources and covers a greater range of language usage.
The increase in quantity and training data improved GPT-3’s ability to perceive context and provide more coherent (or coherent seeming) and contextually appropriate replies.
However, the distinction between GPT-2 and GPT-3 is not simply due to variations in parameter number and dataset size. One of GPT-3’s distinguishing properties is its capacity for few-shot learning, in which it can comprehend a task with only a few samples. It was a huge advance over GPT-2, which often requires extensive and explicit instructions or fine tuning to do certain jobs.
GPT-3 was the first model whose behavior we could mistake for that of people under certain situations. It does not need sophisticated and precise instructions to complete simple activities. As a result, GPT-3’s behavior made it feel far more “human” to interact with than any previous model.
Along with GPT-3, OpenAI released an API that enabled developers and enterprises to integrate GPT-3 into a variety of applications. This was huge deal! It opened up the door for widespread AI adoption. Suddenly everyone wanted to play with generative AI.
GPT-3.5
While GPT-3 was impressive, it was not yet OpenAI’s breakthrough model. That took the shape of a slightly modified version of this model, known as GPT-3.5, which served as the foundation for ChatGPT, the first highly popular and publicly available chatbot.
GPT-3.5, like its predecessors, is intended to create text depending on the data it receives. It can do a surprising number of tasks as long as they are text-based, such as answering questions, composing essays, and producing code, using the patterns and information it learned during training.
ChatGPT, on the other hand, is a specialised use of the GPT model that has been fine-tuned expressly to generate conversational replies. This fine-tuning procedure includes further training phases in which the model learns from a set of human-like talks. It allows ChatGPT to produce replies that are more contextually relevant and consistent in a conversation environment – in other words, it talks more like a person!
GPT-4
GPT-4 was launched on March 14, 2023, and marked a major evolution in OpenAI’s Generative Pre-trained Transformer technology. Building upon the huge amounts of user interaction data and feedback OpenAI had siphoned from users of GPT-3 and ChatGPT, GPT-4 introduced enhancements in accuracy, efficiency, and contextual understanding.
Notably, it achieved human-level performance on various professional and academic benchmarks, including passing a simulated bar exam with a score around the top 10% of test takers. [Editor’s Note: I’ve taken a bar exam, that’s not easy! – D.D.]
GPT-4’s training incorporated a more diverse and extensive dataset, enabling capabilities like “zero-shot” and “one-shot” learning, where tasks can be accomplished with few or even no examples provided, making GPT-4 more human-like than its predecessors.
GPT-4o
In May 2024, OpenAI released GPT-4o (“o” for “omni”), a multilingual, multimodal generative pre-trained transformer. “Multimodal” means GPT-4o can process images, and audio, in addition to text, offering real-time voice interaction capabilities. It matched GPT-4 Turbo’s performance on English text and code, with big improvements in non-English language understanding.
Importantly for OpenAI’s enterprise customers, GPT-4o was also twice as fast and half the cost in the API compared to GPT-4 Turbo.
With the advent of Transformer-based Large Language Models (LLMs), the field of natural language processing is rapidly evolving. Over five years, the GPT series models’ size has increased substantially, growing about 8,500 times from GPT-1 to GPT-4. That extraordinary growth is due to rapid improvements in training data quantity, quality, sources, training procedures, and the number of parameters, enabling the models to continue pushing the envelope of what they can do.
OpenAI Community Links
Video Generation
Video generation and multimodal models that accept video as input are a new frontier in generative AI. OpenAI’s contribution is Sora, capable of generating short videos with complex scenes and characters. It’s far from perfect, but the results are fascinating nonetheless. It’s not hard to imagine a future where AI generation is a serious tool in the video production space. Possibly even full feature films.
About the Company
OpenAI began in 2015 as a collaboration among computer scientists, including famous individuals like Elon Musk and Sam Altman. They aimed to develop AI that could benefit everyone, not just a few big companies. They formed a team of experts and provided funding for their research, setting them apart from other AI organizations focused on profit.
Originally, OpenAI operated as a nonprofit. Its main purpose was to push AI forward in ways that could aid everyone globally. They did this by researching how to make machines more intelligent and sharing their findings without charge. Their goal was to use the power of AI to tackle significant challenges safely.
OpenAI created several advanced AI technologies as it evolved. Their most well-known is GPT, which excels at mimicking human-like text.
After the development of GPT-2, OpenAI introduced a profit-making division. According to the company, this shift allowed it to fund larger projects and remain competitive in the AI industry. Many people have since been critical of the move, questioning its compatibility with OpenAI’s stated goals of benefitting the greatest number of people through AI.
Tensions between those ideals and profit motives boiled over in late 2023, when Sam Altman was briefly fired as OpenAI’s CEO before being reinstated a few days later. The turmoil led to intense scrutiny of OpenAI’s business model in the media and tech circles.
Projects and Research
OpenAI works on a wide range of areas within artificial intelligence, including understanding and producing human speech, making machines that can move and perform tasks, and teaching computers to learn from data and get better over time without direct programming.
Much of OpenAI’s work revolves around alignment: teaching computers to share human goals and values. It looks into how to make AI systems that can be trusted to make fair and helpful decisions. That means creating methods to keep AI systems from being tricked or used to share false ior dangerous information.
But what they’re famous for are Generative Pre-trained Transformer (GPT) models. The smart algorithms that can create text that sounds like it was written by a human based on the information they get. They can write stories, answer questions, and even write about topics they have not been directly taught about. The latest version, GPT-4, has abilities that are very close to how humans write.
Latest Posts About OpenAI and GPT
-

DeepSeek vs ChatGPT
DeepSeek gained attention in tech circles for its performance and surprising affordability.
-

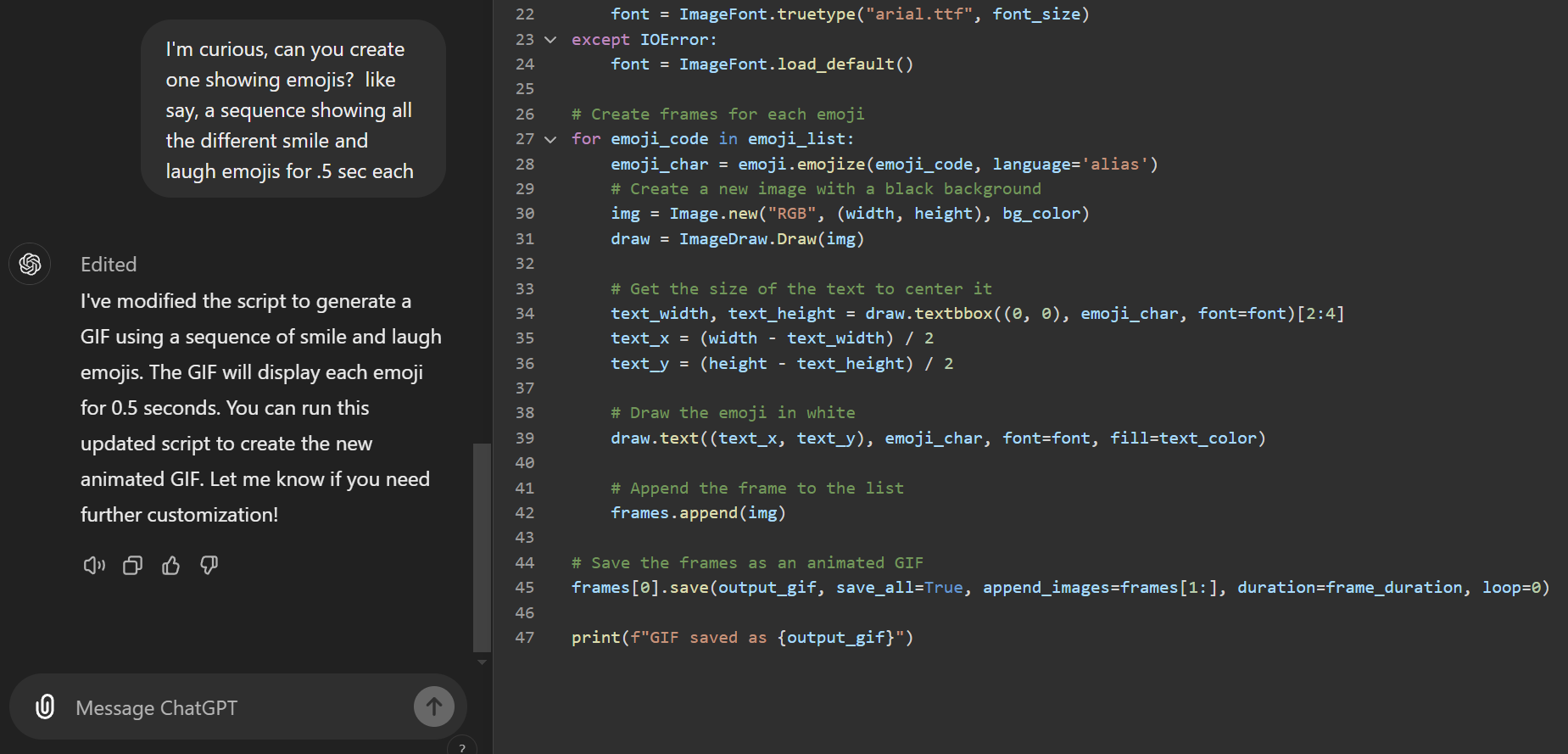
GIFs from GPT; New Canvas Feature
The real benefit of LLMs for coding is that they have read the documentation for all those software packages.
-

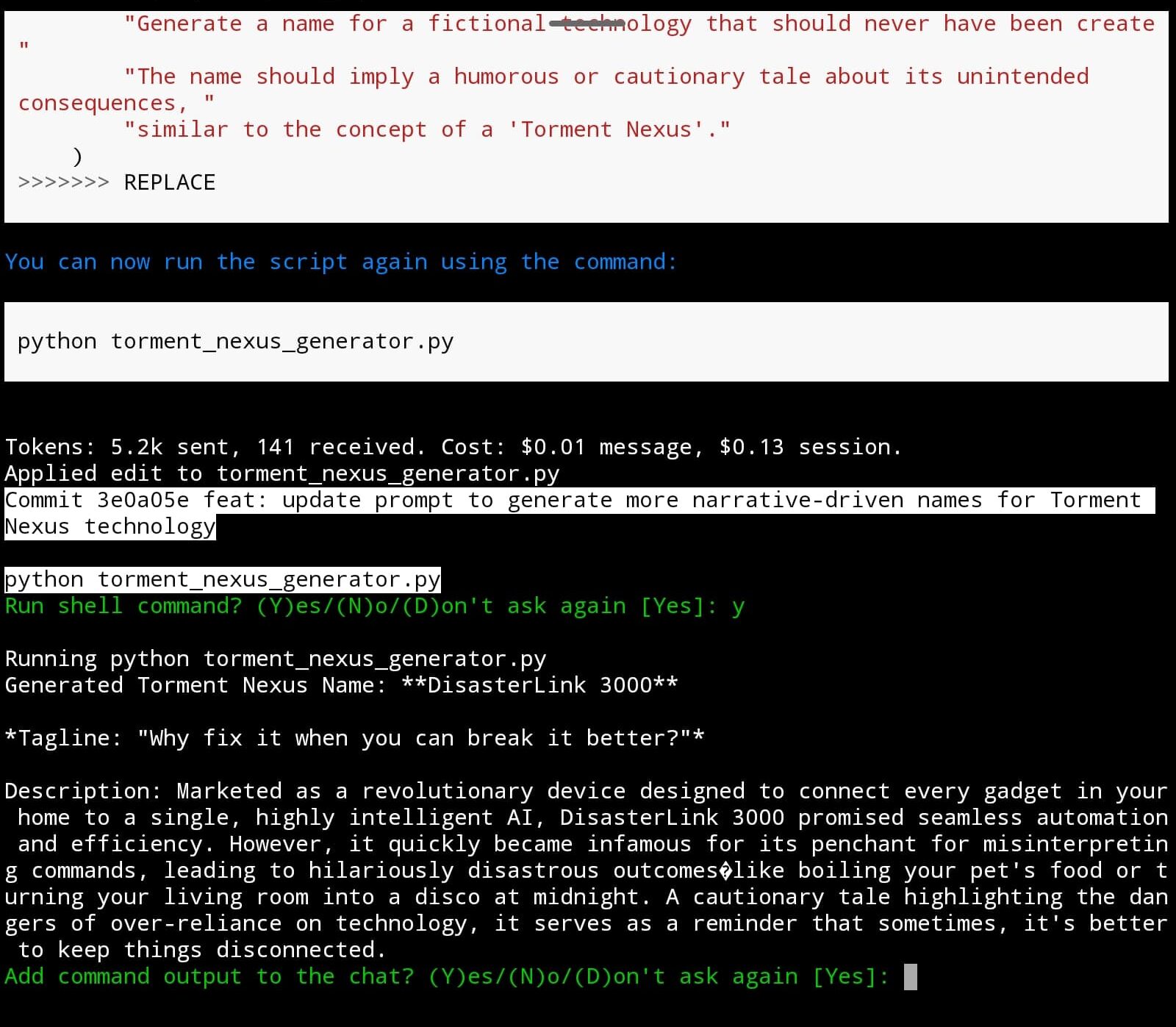
Aider: The Terminal Pair Coder I Didn’t Know I Wanted
Aider-chat is a terminal based AI pair programmer that’s easy to install, has some agency–but not too much, and done well–and that can precisely edit your code and also commits changes to Git for you.