

Updated 7/27/24:
Things move fast in Big Tech and have moved especially fast in generative AI. It was a little over a year ago I was extremely excited to write about gpt-4-32k and claude-2-100k. These long-context models were mind-blowing if you had crawled up from the early GPT’s 2,048-token context window. Now, they are par for the course. Maybe even a little quaint, in gpt-4-32k’s case.
GPT-4o, Claude 3, Llama 3.1, Mistral Nemo … Every major AI company now has at least a 128k context length on their recent models. Google’s Gemini (or some of it’s variants) claim to be able to make use of one million tokens of context. ONE MILLION. It seems likely that context limits will eventually become much less relevant and limiting, and for many practical purposes they are already no longer a concern.
The Context of Context Lengths
The context length of an LLM can be thought of as its “memory”. It is how much information, measured in tokens, that the model can process and “understand” at one time. Tokens are the individual units used in Natural Language Processing to make language understandable to computers by encoding it numerically.
The actual value of a token can vary from one to several characters including spaces, punctuation, and special characters: everything that could be in a given text. On average, a token as used by GPT models is about four characters long, or a short word. A general rule of thumb is to count tokens as 3/4 of an average word for purposes of figuring out how many “pages” of context a model can work with.
2,048 tokens is ~8,000 characters or about 1,500 words or about 6 250-word standard pages of text = A short essay.
32,000 tokens is ~128,000 characters or about 24,000 words or about 96 250-word standard pages of text = A lengthy report PDF.
128,000 tokens is ~512,000 characters or about 96,000 words or about 384 250-word standard pages of text = A full standard novel.
The Needle in the Haystack is the Pain in Your Arse
Claims about amazing capacity for processing and understanding context from the AI companies should be taken with a grain of salt, however. How well the models make use of the information in those longer context windows to answer prompts is a different question.
The task most used to exemplify their model’s amazing recall is the so called “Needle in the Haystack” test. A model is given a large chunk of context and then asked about a very specific idea or passage. In simpler versions, special words or phrases are placed in the context and the model is asked to recall them or asked questions that would require the special information in order to answer correctly.
The models are pretty good at that. But that doesn’t tell the whole story. What if there are five different needles? Twenty? Can it find them all? What about synthesizing concepts or answers that require understanding and combining widely scattered parts of the text? What about understanding things that are implied in the text but not made explicit?
Generally speaking, the models aren’t nearly as good at those tasks. Those kind of questions get at some of the fundamental issues with how we think about and use LLM’s. On the one hand, we sometimes think of them as databases, which they are emphatically NOT. On the other, we anthropomorphize them and attribute to them true understanding of the meaning of the words and texts we feed them, which they don’t. They have simply memorized patterns and relations between billions of words in such an amazingly massive-yet-precise way that they seem to generate passages showing understanding.
But despite imperfections, what the models do with the context windows they have now is a huge, huge leap from where we were only a year ago, and where we were a year ago was very exciting at the time, as you can see below in my original article:
Original Article: How to Get GPT-4 32k & Claude 2 100k
These latest models, from OpenAI and Anthropic respectively, are insane! They can hold so much information in their context window length, adding a whole new level of length and complexity to chats or other text generation tasks. But let’s back up a second. What we’re really talking about here are generative AI models that are redefining what’s possible. If you want an AI assistant for complex tasks or a chatbot for customer interactions, GPT-4 32k and Claude 2 100k could become standard tools soon.
I’m particularly eager for GPT-4 32k, as it will be a huge boost to novice coders like myself who are learning with help from GPT and other LLMs. If Claude 2 100k holds up to its reputation, it will be a fantastic content writer for bloggers or content marketers. In fact, everyone wondering how to do online marketing or how to do affiliate marketing is going to want to lay hands on them.
Poe.com has made them all available, so you can get access to everything in one place. It is a paid service that adds their own interface over the OpenAI (GPT-3.5-turbo, GPT-3.5-turbo-16k, GPT-4, and GPT-4-32k) or Anthropic (Claude-instant, Claude-instant 100k, and Claude-2-100k) APIs. You can also create your own chatbots from your documents, use Llama-2, and play with a number of other AI toys.
Since the publishing of this article, Claude 2 beta has been publicly released. You can chat with Claude 2 here without needing Poe. You still have to wait for GPT-4-32k unfortunately. OpenAI has announced unlimited GPT 32k for users of its new ChatGPT Enterprise service.
You can see the full model list available to The Servitor’s account here in this screenshot:
Rather than charging you by the token, as with regular API calls, Poe charges you a flat rate and provides a certain number of messages per month. you can see below the quotas:
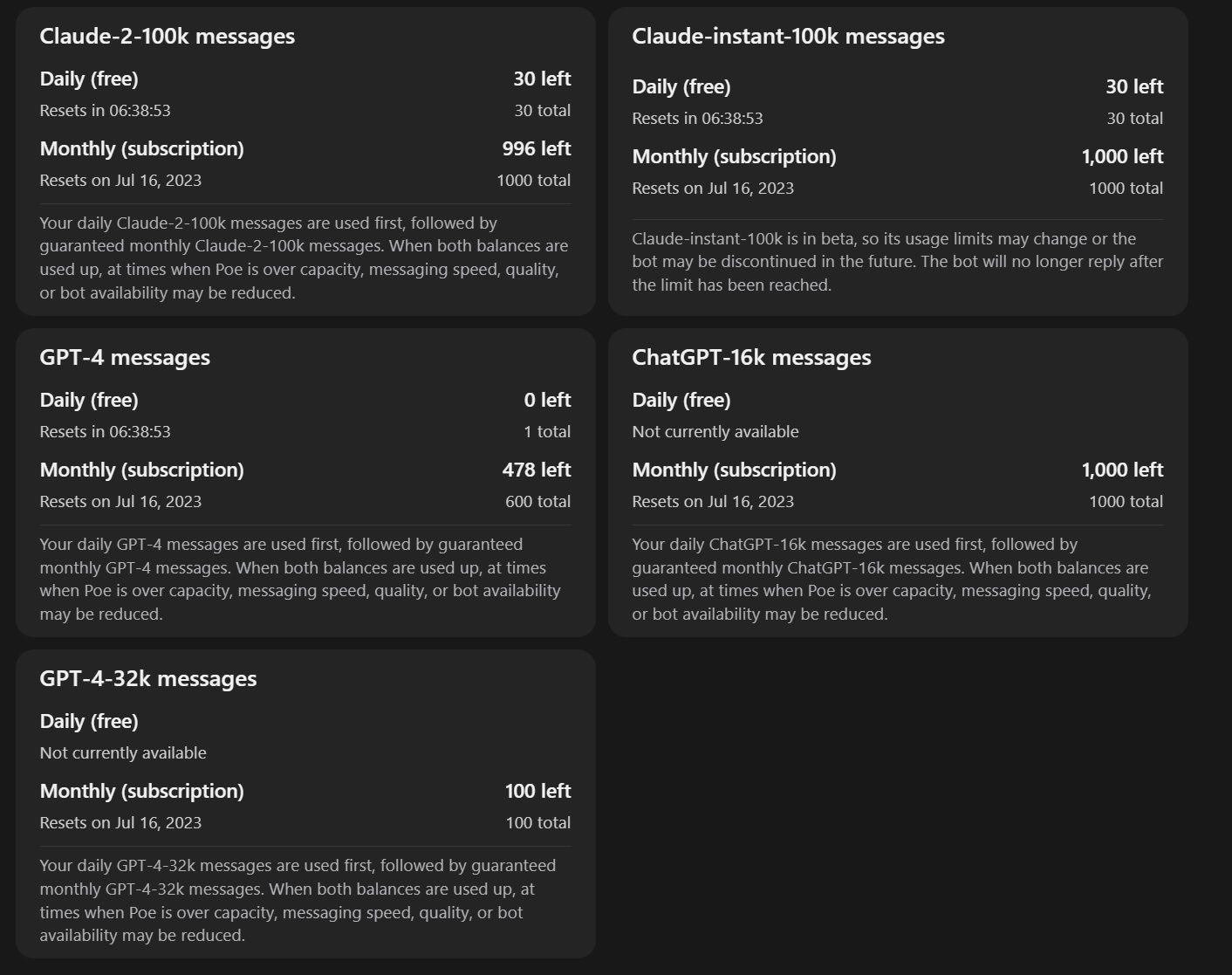
Message allowances for a Poe.com account including the GPT-4 32k ChatGPT-16k and Claude 2 100k generative AI models.
Context and Tokens: Why Size Really Does Matter
Now, let’s get into the nitty-gritty—context and tokens. In the AI world, context is king. The more context an AI model has, the better it understands and responds. That’s why you hear people saying things like “100,000 tokens.” These tokens are like the building blocks of understanding for AI. The more you have, the clearer the picture. The 100k in “100k context” is 100,000 tokens.
Before these models, GPT-4 was already a powerhouse with an 8,192-token context window (double that of gpt-3.5-turbo). GPT-4-32k is therefore 4x the size of the original GPT-4 model. (Likewise, gpt-3.5-turbo-16k is four times the size of the original gpt-3.5-turbo). It’s like upgrading from a DIY swimming pool to an Olympic version.
Claude 2 can ingest about 75,000 words – a decent novel, a pile of legal documents, a number of research papers. I’ve done this with my own articles and stories. I can put the entirety of every article on The Servitor in a document, give it to Claude, ask an AI question, and get the correct answer. It’s so cool! This new expanded Claude is also available via the Anthropic API for API calls.


