
Artificial Intelligence is what it is: artificial. “Artificial” means man-made, false or a copied, like the original but not truly so. That’s what AI is—it is created to emulate the original but, at the end of the day, it’s still fake. But people tend to hyper-focus on the intelligence part, disregarding the artificial aspect, thereby giving more credit to Artificial Intelligence than it really deserves.
Generative AI is trained on existing information on the internet, from social media to websites to PDFs. This enables generative AI to draw from a vast well of information to provide the most accurate responses depending on what it’s asked. Sounds like a neat idea, but there’s a problem.
More on how generative AI and LLMs work: Evolution of Large Language Models
Since the last quarter of 2022, the internet has seen an explosion in the generation of text, images, and audio from AI. Up to 90% of information on the internet is AI output and it’s not slowing down anytime soon. These LLMs need to be trained regularly in order to be updated and provide fresh information. All the “creativity” AI exhibits is derived from humans. Humans are the original foundation for how AI should operate, just more efficient and faster.
Now, since these AIs are generating a significant portion of information on the internet and AI itself needs to be trained, it is being fed its own output.
The Problem of Model Collapse
Researchers think this is a problem. When AI is continuously fed its own data without human intervention, it starts to output gibberish; this phenomenon is referred to as model collapse. It all boils down to human intervention. Humans must be very much involved in the training of AI to filter out nonsense.
Since AI doesn’t really understand the content it is trained on, it can absorb incorrect information as easily as correct information. If the data it is training on was itself created by a “hallucinating” LLM (and they all hallucinate) then you have a problem.
Maybe We Can Feed It CleaneR AI Data. Maybe.
One way data scientists aim to solve this ouroboros dilemma is by feeding the AI synthetic data. Synthetic data is data generated by AI, based on real data sets the AI was originally trained on. It is created using algorithms or models to simulate data structures, patterns, and relationships found in genuine datasets.
This synthetic data is supposed to be of high quality and it’s meant to improve the AI output. It’s already being used in image generation. In a reddit post, a user detailed how he used high quality AI generated photos to design characters with the LoRa (Low Rank Adaptation) technique.
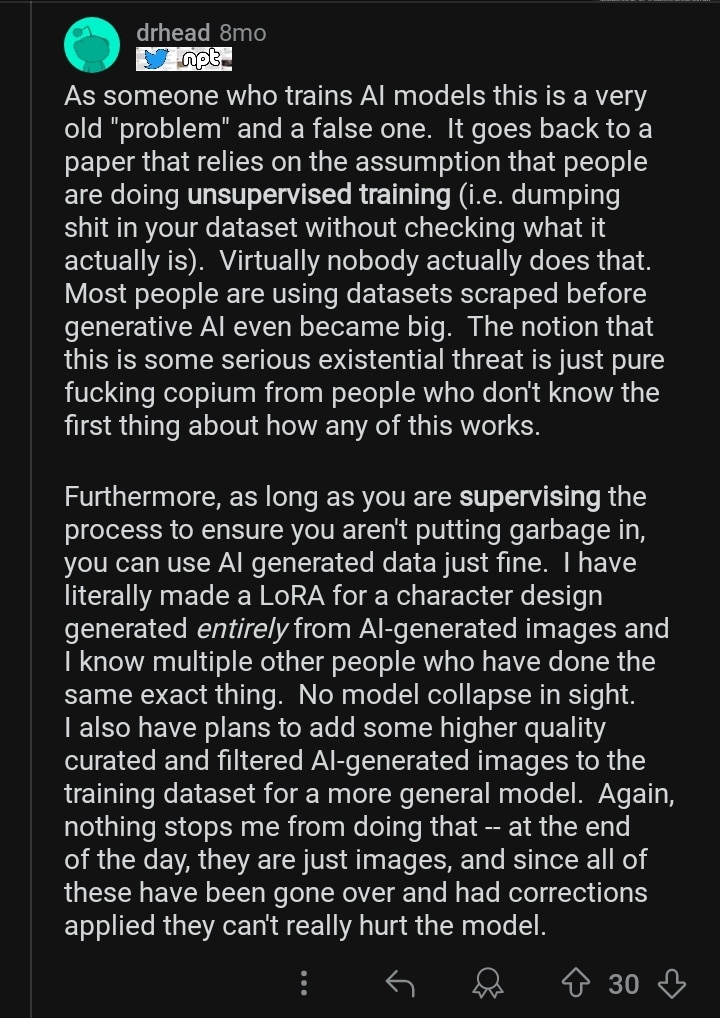
So you see, synthetic data is highly curated before it’s being fed to the LLM. Now, that may sound like a solution but there’s a problem with curation too: automation blindness.
Automation blindness refers to the phenomenon where individuals become overly reliant on or trusting of automated systems to the extent that they may overlook or simply fail to notice important information or potential errors. When someone is including tens or even hundreds of thousands of synthetic data entries, is the data really be “curated”?
These are touchy subjects for people with a lot riding on the current AI hype. Digital inbreeding in artificial intelligence is definitely a real concern even though some tech bros would have you thinking otherwise.


