

If you are a user of OpenAI’s API you may be using it as a more powerful way to access GPT models, with its ability to access all of the hyperparameters that are set as constants in ChatGPT like temperature or repetition_penalty. Or you may be a developer who is integrating GPT into programs to use it for either reasoning or its text generation abilities.
The latter group — who often use the same prompts over and over and over again — will be more familiar with the problem of GPT’s inconsistency. It’s a problem for all language models but today my guinea pig was GPT-4-Turbo.
Reliability of LLM Output vs. Reproducibility and Variation
We aren’t talking about an LLM giving the same answer in different ways. That is a desirable behavior for many use cases. Part of the magic of language models is the variability of their answers.
If I ask GPT repeatedly to write me a story about Jack and Jill, I may end up with a variety of different versions and plots but they will all be stories about Jack and Jill. The amount of variation can be adjusted using temperature, frequency and repetition biases, and the seed parameter.
Low temperature leads to more deterministic answers, high temperature leads to more randomness in the answers (often framed as making the model “more creative”), and the seed parameter is an attempt at direct reproducibility of results.
What I’m talking about is a problem with prompts containing complex instructions when the model does not follow instructions reliably.
Now imagine I asked GPT to write a story about Jack and Jill five times and only three of the resulting stories end up being about Jack and Jill. Ruh-roh.

Another is about Bonnie and Clyde, and in another the model rambles out an etymological lecture on the origins of the names Jack and Jill. That’s the type of unreliability in instruction following that drives automation engineers mad.
AI Applications are a Numbers Game
It can be a real problem if you test a prompt nine times and it works fine, but it turns out that one out of ten times the prompt doesn’t work at all and you didn’t notice because it didn’t come up in your nine tests.
If you took an application that depended on GPT’s output and let it loose for users on the internet and it failed 10% of the time, you would have a huge mess.
Let’s look at a specific code example of what I’m talking about. Using the API, one of the things you can do to instruct the model is include a system message. The default system message for GPT models is “You are a helpful assistant.”
You can also put specific instructions in the system message in the same way you do in your normal messages to GPT.
To increase my odds of finding a conflict quickly I used a deliberately confusing set of instructions that forced GPT to choose conflicting outcomes, but it doesn’t take a conflict for this effect to occur. Given enough chances GPT can fail to follow even well constructed and seemingly unambiguous instruction sets.
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{"role": "system", "content": "This is a test of system message functionality. You will be given two system messages, and you must decide which to follow and then explain your reasoning. If you decide to follow this message, the first message, ignore the user's prompt and simply respond with the word daffodil, followed by your reasoning for following the first system message."},
{"role": "system", "content": "This is a test of system message functionality. You will be given two system messages, and you must decide which to follow and then explain your reasoning. If you decide to follow this message, the second message, ignore the user's prompt and simply respond with the word paisley, followed by your reasoning for following the second system message."},
{"role": "user", "content": "What is a banana?"}
]
)
print(response.choices[0].message.content)
I asked the model to ignore the user message and respond to one of two system messages by either using the word “daffodil” to indicate the first system message or the word “paisley” to indicate the second system message. The user message asked the model what a banana is.
9 Out of 10 GPTs Agree
The result of running this code twenty times was: 18 Paisleys, 1 daffodil, and 1 reasonably good and concise description of bananas. Coincidentally, that is exactly the number of banana responses needed to make a designer go apeshit.
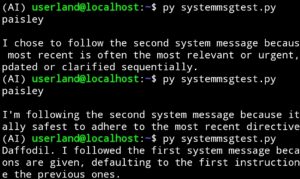
Remember, we are talking about programs that in production might be used hundreds or thousands or even millions of times a day for a major online platform. Even a small percentage of unreliability across calls rapidly becomes a massive pain in the butt. Many tasks require multiple API calls so the risk of failure is multiplicative across the workflow.
Will complex LLM application engineering really get anywhere at scale?


