

Are Our Chatbots Lying to Us?
AI chatbots like ChatGPT, Gemini, and DeepSeek have been getting reasoning upgrades over the past few months. These upgrades are meant to make them better at giving us credible answers. However, recent leaderboard results show they continue to generate false information that sounds convincing.
These errors made by chatbots are known as “hallucinations” and have been a problem from the start. As we’ve previously discussed, hallucinations are one of the biggest challenges in AI, and it’s becoming clear that we may never fully get rid of them. This brings up the question we’ve all been quietly asking: Just how bad is it?
Hallucination: What Is It?
Hallucination is when a large language model (LLM) confidently generates false information and presents it as true. It can also mean an AI response that’s technically correct but doesn’t really answer the question or misses the point in some other way.
Hallucination rates are often expressed as a percentage representing the number of responses that contain an error. Whether a rate is bad depends on context. For an average user, a 1% hallucination rate has little practical effect. 1 in 100 prompts might get a response that has a problem, and that problem might not be obvious or significant. No big deal.
For a software developer or automation engineer, though, even 1% is a potential disaster! When you are managing hundreds of thousands or even millions of LLM requests in an application, and each error potentially represents a system failure or an upset customer, 1% is a matter of dollars and cents.
Hallucination Rates Rise in New AI Models
An OpenAI report showed that its newer models o3 and o4-mini (also called reasoning models), released in April, had higher hallucination rates than the older o1 model from late 2024. OpenAI maintains that the underlying reasoning process is not at fault.
“Hallucinations are not inherently more prevalent in reasoning models, though we are actively working to reduce the higher rates of hallucination we saw in o3 and o4-mini.”
– OpenAI. Source: Stanford Pulse
Turns out, OpenAI isn’t the only one dealing with this. The DeepSeek-R1 model from developer DeepSeek saw a double-digit rise in hallucination rates compared with its previous model, DeepSeek-V2.
Recent Studies: Hallucination Rates of Specific Models
Different studies measure hallucination rates in different ways, leading to competing numbers. Some tests focus on factual accuracy, others on logical coherence or instruction following, and some on outright fabrication.
Vectara’s Hallucination Leaderboard
Vectara’s leaderboard is the most popular and evaluates summarization accuracy. It ranks AI models based on their factual consistency in summarizing documents. Below is a small selection from their leaderboard.
Performance Metrics for Selected Models:
| Model | Accuracy | Hallucination Rate | Average Summary Length |
|---|---|---|---|
| Newer models: | |||
| OpenAI o3-mini-high | 99.2% | 0.8% | 79.5 words |
| OpenAI GPT‑4.5‑Preview | 98.8% | 1.2% | 77.0 words |
| OpenAI GPT‑4o | 98.5% | 1.5% | 77.8 words |
| XAI Grok‑3‑Beta | 97.8% | 2.1% | 97.7 words |
| Older models: | |||
| GPT‑4 | 97.0% | 3.0% | 81.1 words |
| GPT‑3.5 | 96.5% | 3.5% | 84.1 words |
| Llama 2 (70B) | 94.9% | 5.1% | 84.9 words |
| Claude 2 | 91.5% | 8.5% | 87.5 words |
| Google PaLM | 87.9% | 12.1% | 36.2 words |
| Google PaLM‑Chat | 72.8% | 27.2% | 221.1 words |
You can see a bit of the history of LLMs here with very early models like Google’s PaLM being miserably inaccurate, while the godfather of current generation LLMs, GPT-4 marked a milestone in accuracy and low hallucination rates.
Critics have argued that this ranking may not be the best way to compare AI models as it combines different types of hallucination.
“The leaderboard results may not be the best way to judge this technology because LLMs aren’t designed specifically to summarise texts.”
– Emily Bender, University of Washington, Source: NewScientist
Breaking Down Hallucination Rates: Insights from AIMultiple
Tech outfit AI Multiple recently conducted a study to see how often different large language models (LLMs) hallucinate. To test this, they asked 60 fact-based questions pulled from real CNN news articles, covering topics like oil prices, scientific breakthroughs, and art history. Then they compared the models’ answers to the actual facts. Their numbers reflect very different measurement than Vectara.
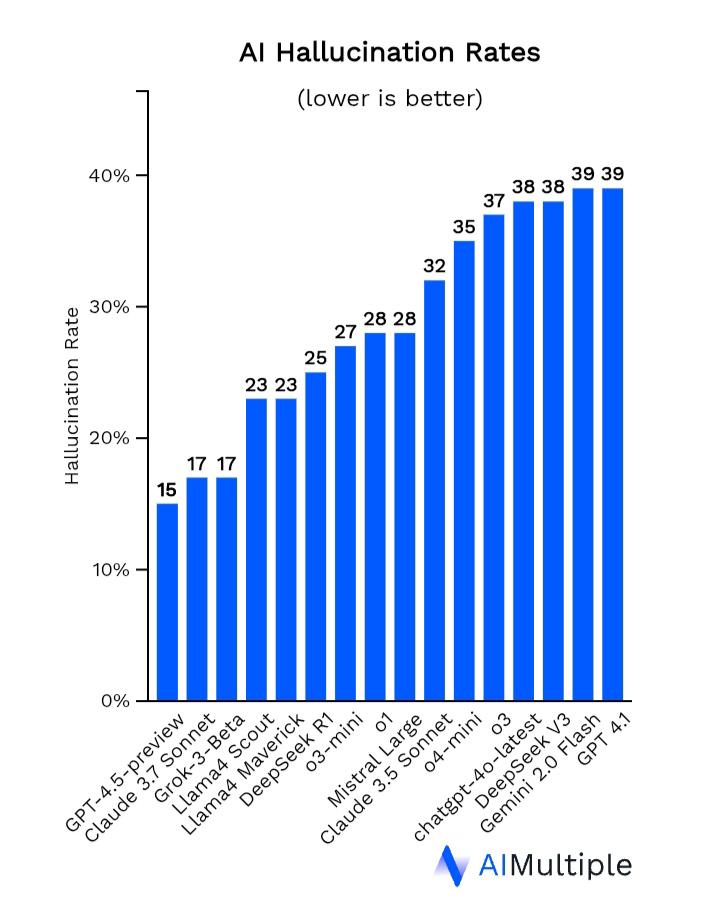
The Results:
- GPT-4.5 (by OpenAI): Had the lowest hallucination rate at just (just?) 15%, making it the most reliable model in their test.
- Other models: A range of models from Anthropic, Mistral, Meta, DeepSeek, Google, and xAI scored between 15-39%. Interestingly, GPT 4.1 was the least accurate, meaning OpenAI had both the least and most accurate models in the AIMultiple review.
The HalluLens Paper (arXiv:2504.17550)
A recent study took a closer look at how often today’s top AI models hallucinate via the new “HalluLens” benchmark framework. The researchers tested a variety of AI models using different tasks to measure how accurate, consistent, and cautious each model is.
Example Results:
GPT-4o (by OpenAI)
Hallucination Rate: 45.15%
Correct Answer Rate: 52.59% (the highest among all tested models)
False Refusal Rate: Just 4.13%
What this means: GPT-4o rarely refused to answer questions and got the most right, but when it did give wrong answers, it was more likely to hallucinate.
Llama-3.1-405B-Instruct
Hallucination Rate: Lowest at 26.84%
False Refusal Rate: High at 56.77%
What this means: This model played it safe, refusing to answer over half the time. As a result, it hallucinated less but also missed a lot of chances to get answers right.
Real World Impact of AI Hallucination
Hallucinations can sometimes help AI models come up with creative or interesting ideas, but they also make it hard to trust them, especially in industries where accuracy really matters. For example:
- An AI model that constantly gives wrong information and always needs fact-checking won’t be a helpful research assistant.
- An AI assistant that hallucinates outdated policies can create serious risks for a company, potentially leading to customer dissatisfaction.
- A law firm wouldn’t be too comfortable using an AI model that adds incorrect details into client contracts.
How Researchers ARE Trying to Stop Hallucinations
Many researchers believe it’s impossible to completely stop AI bots from hallucinating. A range of options have been explored (discussed in more detail here). One idea is teaching AI to express uncertainty.
“Some researchers have proposed teaching AI models uncertainty, or the ability to say, ‘I don’t know,’ to avoid producing falsehoods.”
– Wall Street Journal
Another technique is self‑reflection, where a model is asked to examine it’s own answer for errors and correct them.
The most common in practice is called retrieval-augmented generation or RAG. This method lets the AI search for real documents related to a question before giving an answer, instead of just relying on data stored in its memory. This approach helps ground its responses in real information.
Bottomline: Should You Trust AI CHATBOTS?
If you look at the hallucination rates you can see that anywhere from 1-5%+ of the time an AI answer will contain a flaw. 95% of you’d be safe trusting them. The more important the task, the more sure you need to be the model didn’t mess it up.
You can trust AI chatbots but verify the facts.
In some AI models, hallucination rates are improving, while in others, the risk of error still remains. Until a solution is found, AI hallucinations are just something we have to live with. The safest thing to do is always fact-check everything.

